Основные термины и понятия медицинской статистики
Статистика давно уже стала неотъемлемой частью жизни. С ней люди сталкиваются всюду. На основе статистики делаются выводы о том, где и какие заболевания распространены, что более востребовано в конкретном регионе или среди определенного слоя населения. На основываются даже построения политических программ кандидатов в органы власти. Ими же пользуются и торговые сети при закупке товаров, а производители руководствуются этими данными в своих предложениях.
Статистика играет важную роль в жизни общества и влияет на каждого его отдельного члена даже в мелочах. Например, если по , большинство людей предпочитают темные цвета в одежде в конкретном городе или регионе, то найти яркий желтый плащ с цветочным принтом в местных торговых точках будет крайне затруднительно. Но из каких величин складываются эти данные, оказывающие такое влияние? К примеру, что представляет собой «статистическая значимость»? Что именно понимается под этим определением?
Что это?
Статистика как наука складывается из сочетания разных величин и понятий. Одним из них и является понятие «статистическая значимость». Так называется значение переменных величин, вероятность появления других показателей в которых ничтожно мала.
К примеру, 9 из 10 человек надевают на ноги резиновую обувь во время утренней прогулки за грибами в осенний лес после дождливой ночи. Вероятность того что в какой-то момент 8 из них обуются в парусиновые мокасины - ничтожно мала. Таким образом, в данном конкретном примере число 9 является величиной, которая и называется «статистическая значимость».
Соответственно, если развивать далее приведенный практический пример, обувные магазины закупают к концу летнего сезона резиновые сапожки в большом количестве, чем в другое время года. Так, величина статистического значения оказывает влияние на обычную жизнь.
Разумеется, в сложных подсчетах, допустим, при прогнозе распространения вирусов, учитывается большое число переменных. Но сама суть определения значимого показателя статистических данных - аналогична, вне зависимости от сложности подсчетов и количества непостоянных величин.
Как вычисляют?
Используются при вычислении значения показателя «статистическая значимость» уравнения. То есть можно утверждать, что в этом случае все решает математика. Самым простым вариантом вычисления является цепь математических действий, в которой участвуют следующие параметры:
- два типа результатов, полученных при опросах или изучении объективных данных, к примеру, сумм на которые совершаются покупки, обозначаемые а и b;
- показатель для обеих групп - n;
- значение доли объединенной выборки - p;
- понятие «стандартная ошибка» - SE.
Следующим этапом определяется общий тестовый показатель - t, его значение сравнивается с числом 1,96. 1,96 - это усредненное значение, передающее диапазон в 95 %, согласно функции t-распределения Стьюдента.
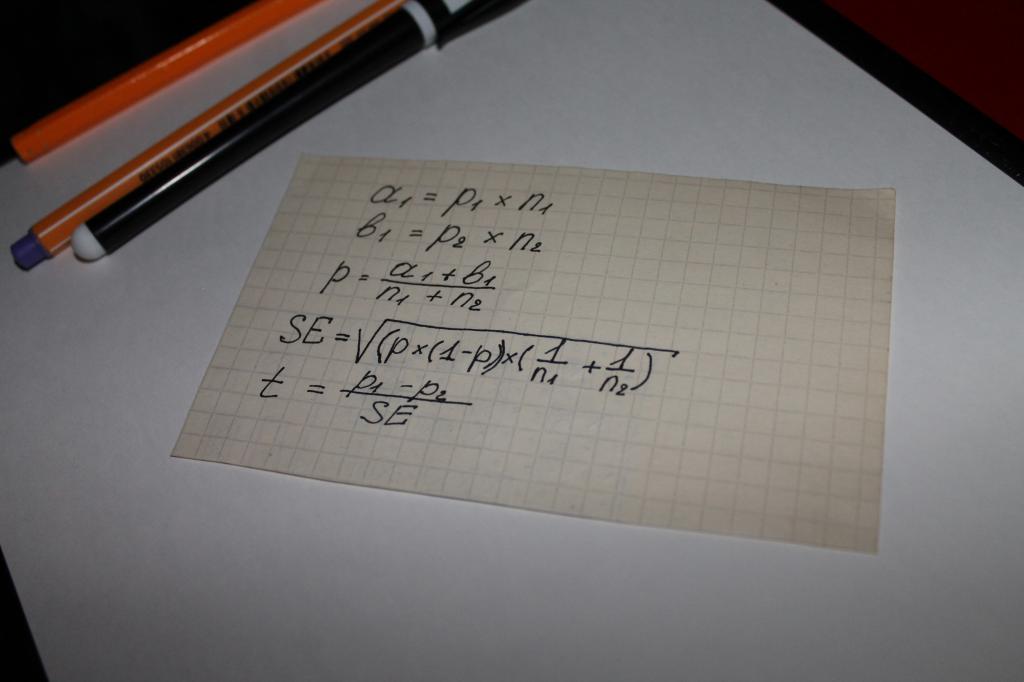
Часто возникает вопрос о том, в чем отличие значений n и p. Этот нюанс просто прояснить при помощи примера. Допустим, вычисляется статистическая значимость лояльности к какому-либо товару или бренду мужчин и женщин.
В этом случае за буквенными обозначениями будет стоять следующее:
- n - число опрошенных;
- p - число довольных продуктом.
Численность опрошенных женщин в этом случае будет обозначено, как n1. Соответственно, мужчин - n2. То же значение будут иметь цифры «1» и «2» у символа p.
Сравнение тестового показателя с усредненными значениями расчетных таблиц Стьюдента и становится тем, что называется «статистическая значимость».
Что понимается под проверкой?
Результаты любого математического вычисления всегда можно проверить, этому учат детей еще в начальных классах. Логично предположить, что раз статистические показатели определяются при помощи цепи вычислений, то и проверяются.
Однако проверка статистической значимости - не только математика. Статистика имеет дело с большим количеством переменных величин и различных вероятностей, далеко не всегда поддающихся расчету. То есть если вернутся к приведенному в начале статьи примеру с резиновой обувью, то логичное построение статистических данных, на которые станут опираться закупщики товаров для магазинов, может быть нарушено сухой и жаркой погодой, которая не типична для осени. В результате этого явления число людей, приобретающих резиновые сапоги, снизится, а торговые точки потерпят убытки. Предусмотреть погодную аномалию математическая формула, разумеется, не в состоянии. Этот момент называется - «ошибка».

Вот как раз вероятность таких ошибок и учитывает проверка уровня вычисленной значимости. В ней учитываются как вычисленные показатели, так и принятые уровни значимости, а также величины, условно называемые гипотезами.
Что такое уровень значимости?
Понятие «уровень» входит в основные критерии статистической значимости. Используется оно в прикладной и практической статистике. Это своего рода величина, учитывающая вероятность возможных отклонений или ошибок.
Уровень основывается на выявлении различий в готовых выборках, позволяет установить их существенность либо же, наоборот, случайность. У этого понятия есть не только цифровые значения, но и их своеобразные расшифровки. Они объясняют то, как нужно понимать значение, а сам уровень определяется сравнением результата с усредненным индексом, это и выявляет степень достоверности различий.

Таким образом, можно представить понятие уровня просто - это показатель допустимой, вероятной погрешности или же ошибки в сделанных из полученных статистических данных выводах.
Какие уровни значимости используются?
Статистическая значимость коэффициентов вероятности допущенной ошибки на практике отталкивается от трех базовых уровней.
Первым уровнем считается порог, при котором значение равно 5 %. То есть вероятность погрешности не превышает уровня значимости в 5 %. Это означает, что уверенность в безупречности и безошибочности выводов, сделанных на основе данных статистических исследований, составляет 95 %.
Вторым уровнем является порог в 1 %. Соответственно, эта цифра означает, что руководствоваться полученными при статистических расчетах данными можно с уверенностью в 99 %.
Третий уровень - 0,1 %. При таком значении вероятность наличия ошибки равна доле процента, то есть погрешности практически исключаются.
Что такое гипотеза в статистике?
Ошибки как понятие разделяются по двум направлениям, касающимся принятия или же отклонения нулевой гипотезы. Гипотеза - это понятие, за которым скрывается, согласно определению, набор иных данных или же утверждений. То есть описание вероятностного распределения чего-либо, относящегося к предмету статистического учета.

Гипотез при простых расчетах бывает две - нулевая и альтернативная. Разница между ними в том, что нулевая гипотеза берет за основу представление об отсутствии принципиальных отличий между участвующими в определении статистической значимости выборками, а альтернативная ей полностью противоположна. То есть альтернативная гипотеза основана на наличии весомой разницы в данных выборок.
Какими бывают ошибки?
Ошибки как понятие в статистике находятся в прямой зависимости от принятия за истинную той или иной гипотезы. Их можно разделить на два направления или же типа:
- первый тип обусловлен принятием нулевой гипотезы, оказавшейся неверной;
- второй - вызван следованием альтернативной.

Первый тип ошибок называется ложноположительным и встречается достаточно часто во всех сферах, где используются статистические данные. Соответственно, ошибка второго типа называется ложноотрицательной.
Для чего нужна регрессия в статистике?
Статистическая значимость регрессии в том, что с ее помощью можно установить, насколько соответствует реальности вычисленная на основе данных модель различных зависимостей; позволяет выявить достаточность или же нехватку факторов для учета и выводов.
Определяется регрессивное значение с помощью сравнения результатов с перечисленными в таблицах Фишера данными. Или же при помощи дисперсионного анализа. Важное значение показатели регрессии имеют при сложных статистических исследованиях и расчетах, в которых участвует большое количество переменных величин, случайных данных и вероятных изменений.
ПЛАТНАЯ ФУНКЦИЯ. Функция статистической значимости доступна только в некоторых тарифных планах. Проверьте, есть ли она в .
Можно узнать, есть ли статистически значимые отличия в ответах, полученных от разных групп респондентов на вопросы в опросе. Для работы с функцией статистической значимости в SurveyMonkey необходимо:
- Включить функцию статистической значимости при добавлении правила сравнения к вопросу в Вашем опросе. Выбрать группы респондентов для сравнения, чтобы отсортировать результаты опроса по группам для наглядного сравнения.
- Изучить таблицы с данными по вопросам Вашего опроса, чтобы выявить наличие статистически значимых отличий в ответах, полученных от различных групп респондентов.
Просмотр статистической значимости
Выполнив нижеописанные действия, Вы сможете создать опрос, отображающий статистическую значимость.
1. Добавьте в опрос вопросы закрытого типа
Для того, чтобы отобразить статистическую значимость во время анализа результатов, Вам понадобится применить правило сравнения к какому-либо вопросу из Вашего опроса.
Применить правило сравнения и вычислить статистическую значимость в ответах можно в том случае, если в схеме опроса Вы используете один из следующих типов вопросов:
Необходимо убедиться в том, что предлагаемые варианты ответа можно разделить на полноценные группы. Варианты ответа, выбираемые Вами для сравнения при создании правила сравнения, будут использованы для организации данных в перекрестные таблицы в рамках всего опроса.
2. Соберите ответы
После завершения составления опроса создайте коллектор для его рассылки. Существует несколько способов .
Вам необходимо получить не менее 30 ответов по каждому варианту ответа, который Вы планируете использовать в своем правиле сравнения, чтобы активировать и просмотреть статистическую значимость.
Пример опроса
Вы хотите узнать, довольны ли мужчины Вашей продукцией значительно больше, чем женщины.
- Добавьте в опрос два вопроса с множественными вариантами ответа:
Какой Ваш пол? (мужской, женский)
Довольны ли Вы или недовольны нашим продуктом? (доволен(-льна), недоволен(-льна)) - Убедитесь, что не менее 30 респондентов выбрали вариант ответа «мужской» на вопрос о поле, А ТАКЖЕ не менее 30 респондентов в качестве своего пола выбрали вариант «женский».
- Добавьте правило сравнения к вопросу "Какой Ваш пол?" и выберите оба варианта ответа как Ваши группы.
- Используйте таблицу данных ниже диаграммы вопроса "Довольны ли Вы или недовольны нашим продуктом?" , чтобы узнать, показывают ли какие-нибудь варианты ответа статистически значимое отличие
Что такое статистически значимое отличие?
Статистически значимое отличие означает, что с помощью статистического анализа установлено наличие существенных отличий между ответами одной группы респондентов и ответами другой группы. Статистическая значимость означает, что полученные цифры достоверно отличаются. Такие знания в значительной мере помогут Вам при анализе данных. Тем не менее, важность полученных результатов определяете Вы. Именно Вы решаете, как толковать результаты опросов и какие меры следует принять на их основе.
Например, Вы получаете больше претензий от покупателей женского пола, чем от покупателей-мужчин. Как определить, является ли такое отличие реальным и требуется ли в связи с этим принять меры? Одним из отличных способов проверить Ваши наблюдения является проведение опроса, который покажет Вам, действительно ли Вашим товаром в значительно большей мере довольны покупатели-мужчины. С помощью статистической формулы предлагаемая нами функция статистической значимости предоставит Вам возможность определить, действительно ли Ваш товар гораздо больше нравится мужчинам, чем женщинам. Это позволит Вам принять меры, основываясь на факты, а не на догадки.
Статистически значимое отличие
Если полученные Вами результаты выделены в таблице данных, это означает, что две группы респондентов значительно отличаются друг от друга. Термин «значительно» не означает, что полученные цифры имеют какую-то особую важность или значение, а лишь то, что между ними есть статистическая разница.
Отсутствие статистически значимого отличия
Если полученные Вами результаты не выделены в соответствующей таблице данных, это означает, что, несмотря на возможную разницу в двух сравниваемых цифрах, между ними нет статистической разницы.
Ответы без статистически значимых отличий демонстрируют, что между двумя сравниваемыми элементами нет значительной разницы при используемом Вами объеме выборки, однако это не обязательно означает, что они не имеют значения. Возможно, увеличив объем выборки, Вы сможете выявить статистически значимое отличие.
Объем выборки
Если у Вас очень малый объем выборки, значительными будут только очень большие отличия между двумя группами. Если у Вас очень большой объем выборки, как небольшие, так и большие отличия будут учтены как значительные.
Тем не менее, если две цифры являются статистически различными, это не означает, что разница между результатами имеет для Вас какое-либо практическое значение. Вам придется самим решить, какие именно отличия значимы для Вашего опроса.
Вычисление статистической значимости
Мы вычисляем статистическую значимость, используя стандартный уровень доверия 95 %. Если вариант ответа отображается как статистически значимый, это означает, что только благодаря случайности либо из-за ошибки выборки отличие между двумя группами имеет место с вероятностью менее 5 % (часто отображается в виде: p<0,05).
Для вычисления статистически значимых отличий между группами мы используем следующие формулы:
|
Параметр |
Описание | |
|---|---|---|
| a1 | Доля участников из первой группы, ответивших на вопрос определенным образом, умноженная на объем выборки данной группы. | |
| b1 | Доля участников из второй группы, ответивших на вопрос определенным образом, умноженная на объем выборки данной группы. | |
| Доля объединенной выборки (p) | Совокупность двух долей из обеих групп. | |
| Стандартная ошибка (SE) | Показатель того, насколько Ваша доля отличается от действительной доли. Меньшее значение означает, что доля близка к действительной доле, большее значение означает, что доля существенно отличается от действительной доли. | |
| Тестовый статистический показатель (t) | Тестовый статистический показатель. Количество значений стандартного отклонения, на которое данное значение отличается от среднего значения. | |
| Статистическая значимость | Если абсолютная величина тестового статистического показателя превышает 1,96* стандартных отклонений от среднего значения, это считается статистически значимым отличием. |
*1,96 является значением, применяемым для уровня доверия 95 %, поскольку 95 % диапазона, обрабатываемого функцией t-распределения Стьюдента, лежит в пределах 1,96 стандартного отклонения от среднего значения.
Пример вычислений
Продолжая пример, используемый выше, давайте выясним, действительно ли процент мужчин, заявляющих о том, что они довольны Вашим товаром, значительно выше процента женщин.
Допустим, в Вашем опросе приняло участие 1000 мужчин и 1000 женщин, и в результате опроса оказалось, что 70 % мужчин и 65 % женщин утверждают, что они довольны Вашим товаром. Является ли показатель на уровне 70 % значительно выше показателя на уровне 65 %?
Подставьте следующие данные из опроса в предлагаемые формулы:
- p1 (% мужчин, довольных продуктом) = 0,7
- p2 (% женщин, довольных продуктом) = 0,65
- n1 (количество опрошенных мужчин) = 1000
- n2 (количество опрошенных женщин) = 1000
Поскольку абсолютная величина тестового статистического показателя больше чем 1,96, это означает, что отличие между мужчинами и женщинами является значительным. По сравнению с женщинами мужчины с большей долей вероятности будут довольны Вашим продуктом.
Скрытие статистической значимости
Как скрыть статистическую значимость для всех вопросов
- Нажмите стрелку «вниз» справа от правила сравнения на левой боковой панели.
- Выберите пункт Редактировать правило .
- Отключите функцию Показать статистическую значимость с помощью переключателя.
- Нажмите кнопку Применить .
Чтобы скрыть статистическую значимость для одного вопроса, необходимо:
- Нажмите кнопку Настроить над диаграммой данного вопроса.
- Откройте вкладку Параметры отображения .
- Снимите флажок напротив пункта Статистическая значимость .
- Нажмите кнопку Сохранить .
Параметр отображения автоматически активируется при включении отображения статистической значимости. Если снять флажок этого параметра отображения, отображение статистической значимости также будет отключено.
Включите функцию статистической значимости при добавлении правила сравнения к вопросу в Вашем опросе. Изучите таблицы с данными по вопросам Вашего опроса, чтобы выявить наличие статистически значимых отличий в ответах, полученных от различных групп респондентов.
Задание 3. Пяти дошкольникам предъявляют тест. Фиксируется время решения каждого задания. Будут ли найдены статистически значимые различия между временем решения первых трёх заданий теста?
|
№ испытуемых | |||
Справочный материал
Данное задание основано на теории дисперсионного анализа. В общем случае, задачей дисперсионного анализа является выявление тех факторов, которые оказывают существенное влияние на результат эксперимента. Дисперсионный анализ может применяться для сравнения средних нескольких выборок, если число выборок больше двух. Для этой цели служит однофакторный дисперсионный анализ.
В целях решения поставленных задач принимается следующее. Если дисперсии полученных значений параметра оптимизации в случае влияния факторов отличаются от дисперсий результатов в случае отсутствия влияния факторов, то такой фактор признается значимым.
Как видно из формулировки задачи, здесь используются методы проверки статистических гипотез, а именно – задача проверки двух эмпирических дисперсий. Следовательно, дисперсионный анализ базируется на проверке дисперсий по критерию Фишера. В данном задании необходимо проверить являются ли статистически значимыми различия между временем решения первых трёх заданий теста каждым из шести дошкольников.
Нулевой (основной) называют выдвинутую гипотезу H о. Сущность е сводится к предположению, что разница между сравниваемыми параметрами равна нулю (отсюда и название гипотезы – нулевая) и что наблюдаемые различия имеют случайный характер.
Конкурирующей (альтернативной) называют гипотезу H 1 , которая противоречит нулевой.
Решение:
Методом дисперсионного анализа при уровне значимости α = 0,05 проверим нулевую гипотезу (H о) о существовании статистически значимых различий между временем решения первых трёх заданий теста у шести дошкольников.
Рассмотрим таблицу условия задания, в которой найдем среднее время решения каждого из трех заданий теста
|
№ испытуемых |
Уровни фактора |
||
|
Время решения первого задания теста (в сек.). |
Время решения второго задания теста (в сек.). |
Время решения третьего задания теста (в сек.). |
|
|
Групповая средняя | |||
Находим общую среднюю:
Для того, чтобы учесть значимость временных различий каждого теста, общая выборочная дисперсия разбивается на две части, первая из которых называется факторной , а вторая – остаточной
Рассчитаем общую сумму квадратов отклонений вариант от общей средней по формуле
или
![]() ,
где р – число измерений времени решений
заданий теста, q – количество испытуемых.
Для этого составим таблицу квадратов
вариант
,
где р – число измерений времени решений
заданий теста, q – количество испытуемых.
Для этого составим таблицу квадратов
вариант
|
№ испытуемых |
Уровни фактора |
||
|
Время решения первого задания теста (в сек.). |
Время решения второго задания теста (в сек.). |
Время решения третьего задания теста (в сек.). |
|
ДОСТОВЕРНОСТЬ СТАТИСТИЧЕСКАЯ
- англ. credibility /validity, statistical; нем. Validitat, statistische. Последовательность, объективность и отсутствие неясности в статистическом тесте или в к.-л. наборе измерений. Д. с. может быть проверена повторением того же теста (или вопросника) по отношению к тому же самому субъекту, чтобы убедиться, будут ли получены такие же результаты; или сравнением различных частей теста, которыми предполагают измерить один и тот же объект.
Antinazi. Энциклопедия социологии , 2009
Смотреть что такое "ДОСТОВЕРНОСТЬ СТАТИСТИЧЕСКАЯ" в других словарях:
ДОСТОВЕРНОСТЬ СТАТИСТИЧЕСКАЯ - англ. credibility /validity, statistical; нем. Validitat, statistische. Последовательность, объективность и отсутствие неясности в статистическом тесте или в к. л. наборе измерений. Д. с. может быть проверена повторением того же теста (или… … Толковый словарь по социологии
В статистике величину называют статистически значимой, если мала вероятность её случайного возникновения или еще более крайних величин. Здесь под крайностью понимается степень отклонения тестовой статистики от нуль гипотезы. Разница называется… … Википедия
Физическое явление статистической устойчивости состоит в том, что при увеличении величины выборки частота случайного события или среднее значение физической величины стремится к некоторому фиксированному числу. Феномен статистической… … Википедия
ДОСТОВЕРНОСТЬ РАЗЛИЧИЯ (сходства) - аналитико статистическая процедура установления уровня значимости различий или сходств между выборками по изучаемым показателям (переменным) … Современный образовательный процесс: основные понятия и термины
ОТЧЕТНОСТЬ, СТАТИСТИЧЕСКАЯ Большой бухгалтерский словарь
ОТЧЕТНОСТЬ, СТАТИСТИЧЕСКАЯ - форма государственного статистического наблюдения, при которой соответствующие органы получают от предприятий (организаций и учреждений) необходимые им сведения в виде уставленных в законном порядке отчетных документов (статистических отчетов) за … Большой экономический словарь
Наука, занимающаяся изучением приемов систематического наблюдения над массовыми явлениями социальной жизни человека, составления численных их описаний и научной обработки этих описаний. Таким образом, теоретическая статистика есть наука… … Энциклопедический словарь Ф.А. Брокгауза и И.А. Ефрона
Коэффициент корреляции - (Correlation coefficient) Коэффициент корреляции это статистический показатель зависимости двух случайных величин Определение коэффициента корреляции, виды коэффициентов корреляции, свойства коэффициента корреляции, вычисление и применение… … Энциклопедия инвестора
Статистика - (Statistics) Статистика это общетеоретическая наука, изучающая количественные изменения в явлениях и процессах. Государственная статистика, службы статистики, Росстат (Госкомстат), статистические данные, статистика запросов, статистика продаж,… … Энциклопедия инвестора
Корреляция - (Correlation) Корреляция это статистическая взаимосвязь двух или нескольких случайных величин Понятие корреляции, виды корреляции, коэффициент корреляции, корреляционный анализ, корреляция цен, корреляция валютных пар на Форекс Содержание… … Энциклопедия инвестора
Книги
- Исследование в математике и математика в исследовании: Методический сборник по исследовательской деятельности учащихся , Борзенко В.И.. В сборнике представлены методические разработки, применимые в организации исследовательской деятельности учащихся. Первая часть сборника посвящена применению исследовательского подхода в…
Основные черты всякой зависимости между переменными.
Можно отметить два самых простых свойства зависимости между переменными: (a) величина зависимости и (b) надежность зависимости.
- Величина . Величину зависимости легче понять и измерить, чем надежность. Например, если любой мужчина в выборке имел значение числа лейкоцитов (WCC) выше чем любая женщина, то вы можете сказать, что зависимость между двумя переменными (Пол и WCC) очень высокая. Другими словами, вы могли бы предсказать значения одной переменной по значениям другой.
- Надежность ("истинность"). Надежность взаимозависимости - менее наглядное понятие, чем величина зависимости, однако чрезвычайно важное. Надежность зависимости непосредственно связана с репрезентативностью определенной выборки, на основе которой строятся выводы. Другими словами, надежность говорит о том, насколько вероятно, что зависимость будет вновь обнаружена (иными словами, подтвердится) на данных другой выборки, извлеченной из той же самой популяции.
Следует помнить, что конечной целью почти никогда не является изучение данной конкретной выборки значений; выборка представляет интерес лишь постольку, поскольку она дает информацию обо всей популяции. Если исследование удовлетворяет некоторым специальным критериям, то надежность найденных зависимостей между переменными выборки можно количественно оценить и представить с помощью стандартной статистической меры.
Величина зависимости и надежность представляют две различные характеристики зависимостей между переменными. Тем не менее, нельзя сказать, что они совершенно независимы. Чем больше величина зависимости (связи) между переменными в выборке обычного объема, тем более она надежна (см. следующий раздел).
Статистическая значимость результата (p-уровень) представляет собой оцененную меру уверенности в его "истинности" (в смысле "репрезентативности выборки"). Выражаясь более технически, p-уровень – это показатель, находящийся в убывающей зависимости от надежности результата. Более высокий p-уровень соответствует более низкому уровню доверия к найденной в выборке зависимости между переменными. Именно, p-уровень представляет собой вероятность ошибки, связанной с распространением наблюдаемого результата на всю популяцию.
Например, p-уровень = 0.05 (т.е. 1/20) показывает, что имеется 5% вероятность, что найденная в выборке связь между переменными является лишь случайной особенностью данной выборки. Во многих исследованиях p-уровень 0.05 рассматривается как "приемлемая граница" уровня ошибки.
Не существует никакого способа избежать произвола при принятии решения о том, какой уровень значимости следует действительно считать "значимым". Выбор определенного уровня значимости, выше которого результаты отвергаются как ложные, является достаточно произвольным.
На практике окончательное решение обычно зависит от того, был ли результат предсказан априори (т.е. до проведения опыта) или обнаружен апостериорно в результате многих анализов и сравнений, выполненных с множеством данных, а также на традиции, имеющейся в данной области исследований.
Обычно во многих областях результат p .05 является приемлемой границей статистической значимости, однако следует помнить, что этот уровень все еще включает довольно большую вероятность ошибки (5%).
Результаты, значимые на уровне p .01 обычно рассматриваются как статистически значимые, а результаты с уровнем p .005 или p . 001 как высоко значимые. Однако следует понимать, что данная классификация уровней значимости достаточно произвольна и является всего лишь неформальным соглашением, принятым на основе практического опыта в той или иной области исследования .
Понятно, что чем большее число анализов будет проведено с совокупностью собранных данных, тем большее число значимых (на выбранном уровне) результатов будет обнаружено чисто случайно.
Некоторые статистические методы, включающие много сравнений, и, таким образом, имеющие значительный шанс повторить такого рода ошибки, производят специальную корректировку или поправку на общее число сравнений. Тем не менее, многие статистические методы (особенно простые методы разведочного анализа данных) не предлагают какого-либо способа решения данной проблемы.
Если связь между переменными "объективно" слабая, то не существует иного способа проверить такую зависимость кроме как исследовать выборку большого объема. Даже если выборка совершенно репрезентативна, эффект не будет статистически значимым, если выборка мала. Аналогично, если зависимость "объективно" очень сильная, тогда она может быть обнаружена с высокой степенью значимости даже на очень маленькой выборке.
Чем слабее зависимость между переменными, тем большего объема требуется выборка, чтобы значимо ее обнаружить.
Разработано много различных мер взаимосвязи между переменными. Выбор определенной меры в конкретном исследовании зависит от числа переменных, используемых шкал измерения, природы зависимостей и т.д.
Большинство этих мер, тем не менее, подчиняются общему принципу: они пытаются оценить наблюдаемую зависимость, сравнивая ее с "максимальной мыслимой зависимостью" между рассматриваемыми переменными. Говоря технически, обычный способ выполнить такие оценки заключается в том, чтобы посмотреть, как варьируются значения переменных и затем подсчитать, какую часть всей имеющейся вариации можно объяснить наличием "общей" ("совместной") вариации двух (или более) переменных.
Значимость зависит в основном от объема выборки. Как уже объяснялось, в очень больших выборках даже очень слабые зависимости между переменными будут значимыми, в то время как в малых выборках даже очень сильные зависимости не являются надежными.
Таким образом, для того чтобы определить уровень статистической значимости, нужна функция, которая представляла бы зависимость между "величиной" и "значимостью" зависимости между переменными для каждого объема выборки.
Такая функция указала бы точно "насколько вероятно получить зависимость данной величины (или больше) в выборке данного объема, в предположении, что в популяции такой зависимости нет". Другими словами, эта функция давала бы уровень значимости
(p -уровень), и, следовательно, вероятность ошибочно отклонить предположение об отсутствии данной зависимости в популяции.
Эта "альтернативная" гипотеза (состоящая в том, что нет зависимости в популяции) обычно называется нулевой гипотезой .
Было бы идеально, если бы функция, вычисляющая вероятность ошибки, была линейной и имела только различные наклоны для разных объемов выборки. К сожалению, эта функция существенно более сложная и не всегда точно одна и та же. Тем не менее, в большинстве случаев ее форма известна, и ее можно использовать для определения уровней значимости при исследовании выборок заданного размера. Большинство этих функций связано с классом распределений, называемым нормальным .











